

By Helen Hill for MGHPCC
David Kaeli heads the Northeastern University Computer Architecture Research (NUCAR) Laboratory, a group focused on the performance and design of high-performance computer systems and software.
While the remarkable advances that have been made in sensor-based and data-driven science over the past two decades have largely been occurred on the back of Moore's Law, there is a growing consensus that similarly rapid growth cannot be relied on to last for ever. To address this Kaeli and his group are exploring how advances in software and algorithm development can accelerate computation to increase the scale and complexity of problems that can be tackled.
Several students from the NUCAR lab shared their research as part of the HPC Day 2018 workshop held at Northeastern University in May. Here we spotlight three projects, one from a group who have been testing how machine learning techniques can be used to improve medical imaging, another from a group who have been trying to develop a better understanding of transient errors, and a third who have been assessing the effectiveness of novel high level synthesis approaches in increasing the attractiveness of FPGA architectures.
Denoising Monte Carlo Photon Transport Simulations
Leiming Yu, Yaoshen Yuan, Zhao Hang, David Kaeli, and Qianqian Fang
click here for pdf
Monte Carlo (MC) methods are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. They are considered to be the gold standard for modeling light propagation in turbid media, such as human tissue, and as such can be found at the heart of many medical imaging technologies. However MC-based simulations are inherently noisy, and while increasing the number of simulated photons reduces the amount of stochastic noise, it does so at the cost of proportionately increased run times.
Having previously explored using a Graphics Processing Unit (GPU) accelerated noise-adaptive non-local mean (ANLM) filter to improve low-photon MC simulations, new work from Leiming Yu et al, has been exploring neural network techniques to help denoise its MC photon transport simulations. Implementing a denoising neural network model to learn the noise, and to learn the photon energy degradation contour, in place of using an ANLM filter, the team were able to demonstrate a four fold improvement in the signal-to-noise ratio from their ANLM filtered simulations. They also showed that their denoised low-photon simulations result can attain comparable quality to one generated from a simulation with two or three orders of magnitude more photons.
The team is now turning its attention to using their neural network model to improve the intensity of the light source.
Transient Fault Handling and GPU Program Vulnerability
Charu Kalra, Fritz Previlon, and David Kaeli
click here for pdf
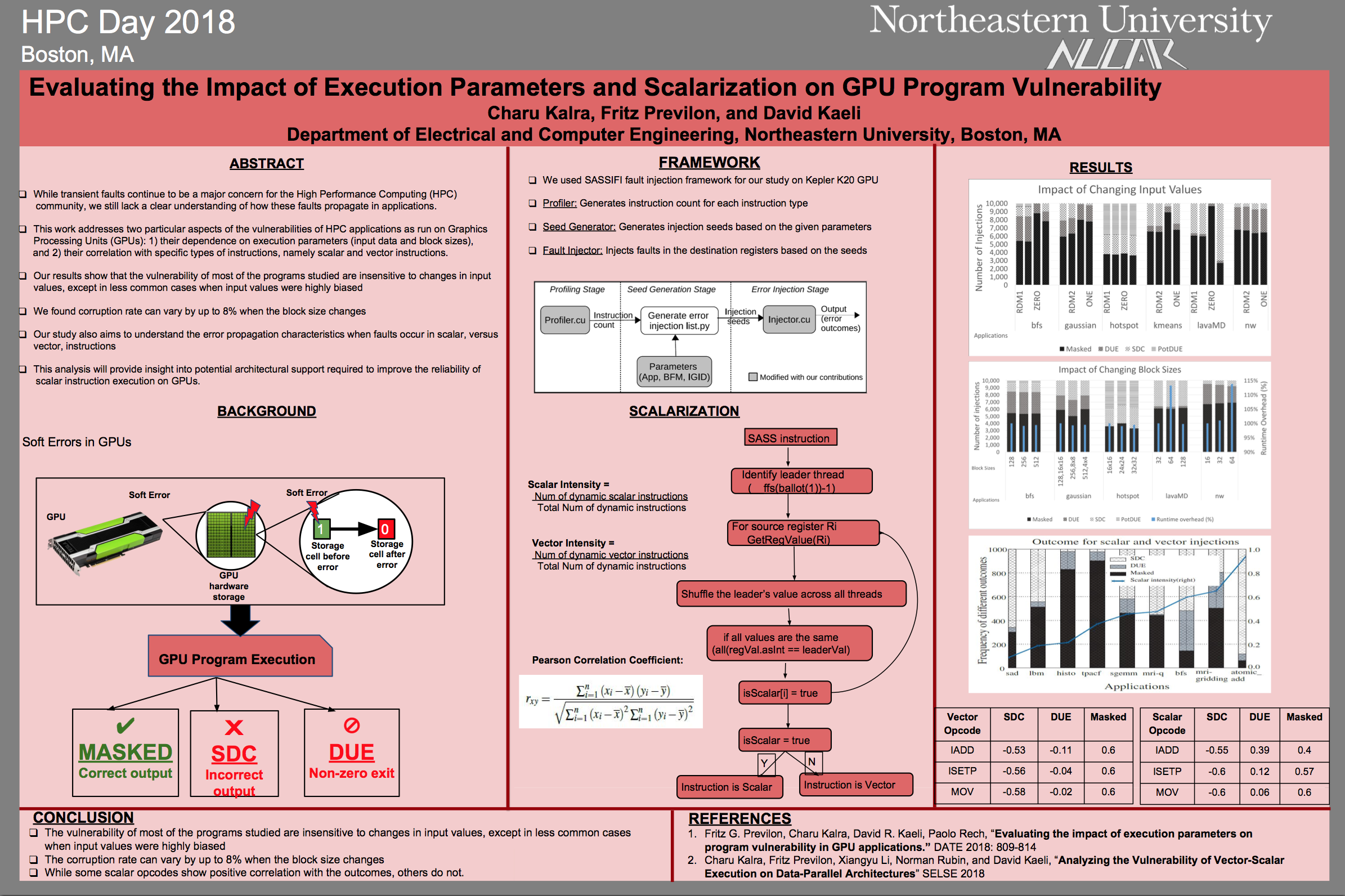
While transient faults remain a major concern for the High Performance Computing (HPC) community, computer scientists continue to lack a clear understanding of how such faults propagate within applications.
Working with Fritz Previlon and David Kaeli, Charu Kalra has been exploring two particular aspects of the vulnerabilities of HPC applications run on GPUs: their dependence on execution parameters (input data and block size), and their correlation with specific types of instructions, in particular scalar and vector type instructions.
The results Kalra presented at HPC Day 2018 show that the vulnerability of most of the programs studied was insensitive to changes in input values, except in less common cases when input values were highly biased but that corruption rates could vary by up to 8% when the block size changed.
In their work distinguishing the error propagation characteristics when faults occur in scalar, versus vector instructions, results left room for further work with the team finding that while some scalar opcodes showed positive correlation with outcome behaviors, others do not.
High Level Synthesis Approaches
Nicolas Bohm Agostini, Elmira Karimi, Jose Abellan, and David Kaeli.

click here for pdf
With a stalling of CPU clock frequency, a measure of processor speed, the HPC community has started looking into alternative architectures to speed processing time. Chief among the candidates are multicore-CPU, GPU, FPGA (Field Programmable Gate Array) and ASIC (applications Specific Integrated Circuit) architectures, however although each has its strengths and weaknesses, until now, despite performance and power consumption being critical factors where CPUs and GPUs tend to lag, the HPC community has typically focused its attention on them due to ease of use and performance considerations.
Motivated by recent advances in High Level Synthesis (HLS) tools which promise to bridge the "Ease of Use" gap that prevents FPGA accelerators from becoming mainstream, Bohm et al. have been exploring how the rise of new HLS development tools capable of making FPGA architectures easier to leverage could impact the HPC architectural landscape.
The team found that FPGA platforms exhibit good performances with great power efficiency, as compared to CPU and GPU platform solutions, while HLS tools are already capable of delivering similar performance to CPU platforms while also simplifying their programming flow. They expect increased use of FPGAs to increase platform adoption, in turn increasing interest from the research community, likely leading to more breakthroughs.
Story image: Shutterstock
David Kaeli
Northeastern University Computer Architecture Research (NUCAR) Laboratory






