

UMass NET2 and Harvard NESE teams come together to showcase advanced networking and storage technologies, with NESE achieving sustained transfers of 700 Gb/s, paving the way for future large-scale scientific workflows.
Story provided by Rafael Coelho Lopes de Sa (NET2, UMass), Eduardo Bach (NET2, UMass), and Milan Kupcevic (NESE, Harvard).
The 2025 edition of the annual International Conference for High Performance Computing, Networking, Storage, and Analysis Conference (SC25) just wrapped up in St. Louis this week with over 16,500 attendees. As in previous years, the MGHPCC was present during the conference showcasing almost 80 computationally intensive research projects being conducted at the center as well as the new partnership with the Massachusetts AI Hub.
A novelty this year, the MGHPCC participated for the first time in the Network Research Exhibitions (NRE) event of SC25. Around 20 NREs were organized this year to showcase achievements in High Performance Computing, Networking, Storage, and Analysis. Led by the NET2 team from the University of Massachusetts Amherst, our NRE demonstrated advanced data-transfer capabilities of the NESE system at the MGHPCC.

Two years ago, as part of NESE’s mission to create a data-centric infrastructure via co-design with science projects at the MGHPCC, UMass Senior Research Scientist Eduardo Bach and Harvard Senior Engineer Milan Kupcevic launched a new dCache service optimized for high-throughput computing systems. At the MGHPCC, the system has been essential for the NET2 cluster which receives large amounts of data from the Large Hadron Collider at CERN for processing.
To be able to transfer data to national and international collaborators with a bandwidth that matches the throughput of the dCache NESE cluster, the system was equipped with advanced capabilities which benefit from collaborative projects at the MGHPCC. Funded by an NSF CC* project (OAC-2346286, UMass PI Rafael Coelho Lopes de Sa), the dCache system was connected via the regional network NEREN to two 400Gb/s-capable WAN links between the MGHPCC, NYC and Boston. In NYC and Boston, the system peers with major research networks like ESnet and Internet2, private internet providers, and testbeds like the NSF FABRIC network. The new connections were configured at the MGHPCC by UMass engineer Jessa Westclark, and the integration with NESE was performed by Harvard engineer Nick Amento.
The two new network connections were integrated into the ESnet SENSE orchestrator project which allows for the creation of dedicated internet connections with high quality-of-service between data centers and labs across the world. Through SENSE, they can be turned into on‑demand, software‑defined circuits with reserved bandwidth. The ability to create high quality-of-service, experiment‑specific network paths will be critical for the next generation of data‑intensive science.
Our NRE demonstration aimed to transfer data at a rate of 800 Gb/s between the NESE disk servers and National Research Platform (NRP) servers in the SCinet cluster on the SC25 show floor. Achieving this with real disk storage, rather than simpler memory‑to‑memory tests, required deep optimization of the full grid data‑transfer stack on 38 commodity storage servers. Bach and Kupcevic led kernel‑level optimization on each node and cluster‑level optimization of the dCache service to match the SENSE‑provisioned network capacity.
With the optimized NESE dCache cluster and high‑priority SENSE circuits, the demonstration sustained 700 Gb/s from MGHPCC to the SC25 show floor and almost 400 Gb/s in the reverse direction. All transfers used the same grid tools and workflows that move LHC data from CERN to MGHPCC today, directly exercising the production path needed for the High-Luminosity LHC era and for other next-generation projects that rely on large amounts of data.
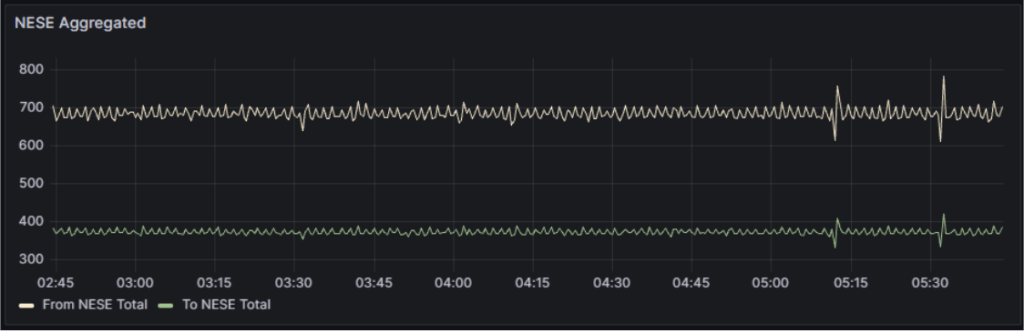
With the fully optimized NESE dCache cluster and the high-priority SENSE network, the demonstration sustained 700 Gb/s from MGHPCC to the SC25 show floor and almost 400 Gb/s in the reverse direction. All transfers used the same grid tools and workflows that move LHC data from CERN to MGHPCC today, demonstrating our readiness to the HL-LHC project and for other future large‑scale projects.
The NRP system was used by several NRE demonstrations during SC25, with the highest throughput coming, by a large margin, from NESE. These results open the doors for even higher transfer rates with modern NVMe storage and multi-Tb/s network connections.
Over the three days of exhibition, more than 200 PB of data was transferred in and out of the SCinet cluster. In addition to the volume of data, the demonstration showcased advanced capabilities of the NESE dCache system that will be critical for next‑generation experiments: high‑priority network connections with reserved bandwidth (in collaboration with ESnet, as described above) and FPGA‑based tools for packet marking, monitoring, and routing (in collaboration with the OCT project at MGHPCC). Together with SENSE and NRP, these capabilities make MGHPCC, NET2, and NESE a practical platform where large collaborations can prototype and operate end‑to‑end workflows.
The authors of NRE124 would like to acknowledge the contributions of the UMass Information Technology to the SCinet cluster (at the silver level) and the WAN connection from NYC and Boston to St. Louis provided by Zayo and ESnet. The authors of NRE124 would also like to thank the collaboration with NESE/MGHPCC, NET2/MGHPCC, OCT/MGHPCC, UMass Research computing, Harvard Research Computing, NEREN, NSF FABRIC, National Research Platform, and the DOE ESnet.
MGHPCC Goes to SC25 (MGHPCC News)






